概述
本文主要介绍常用的排序算法,常用到的排序算法有十中左右,但是在稳定性和时间空间复杂度上存在差异,有时候可以结合使用以达到最高的性能。
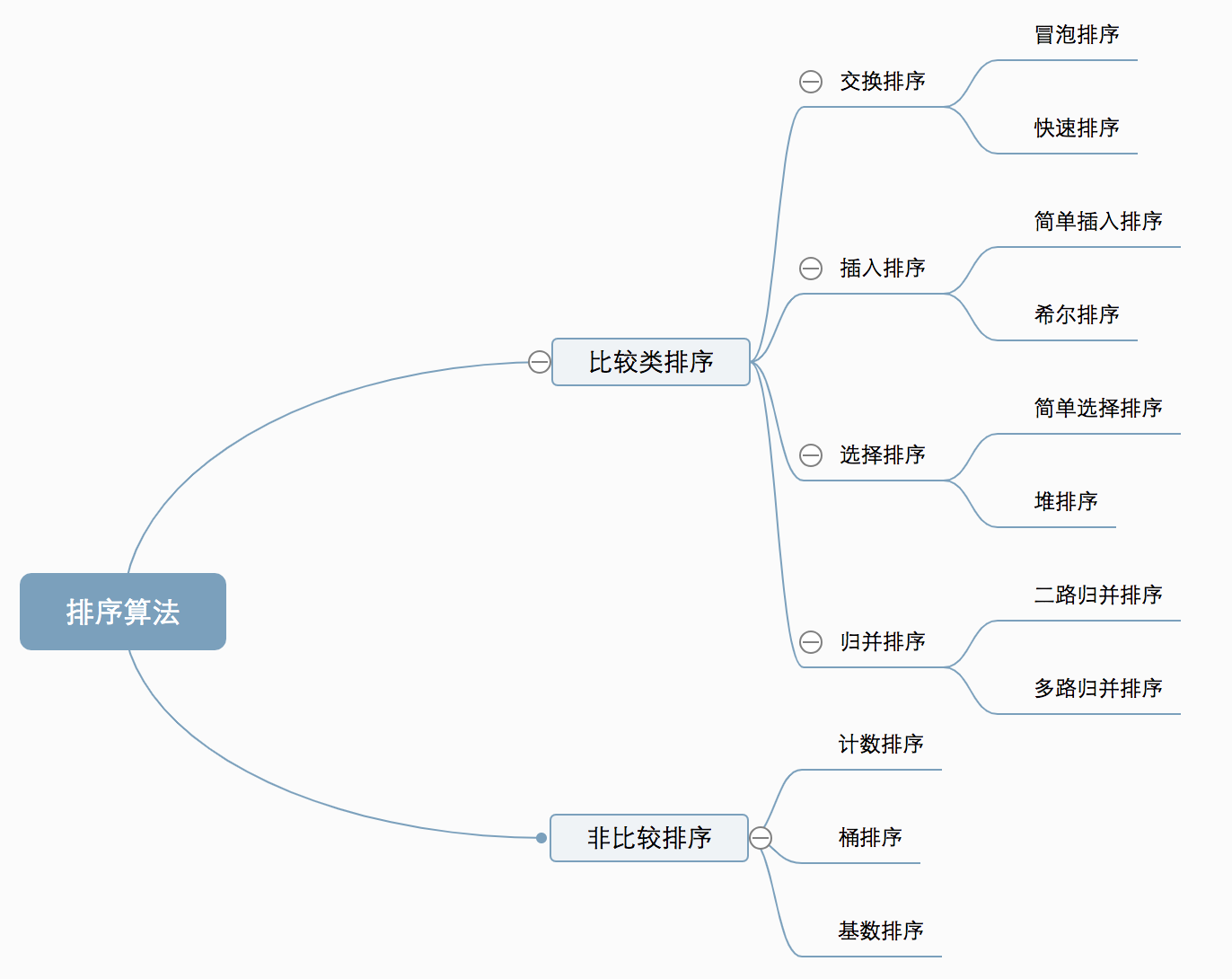
算法分类
常用的排序算法有如下几种
性能对比
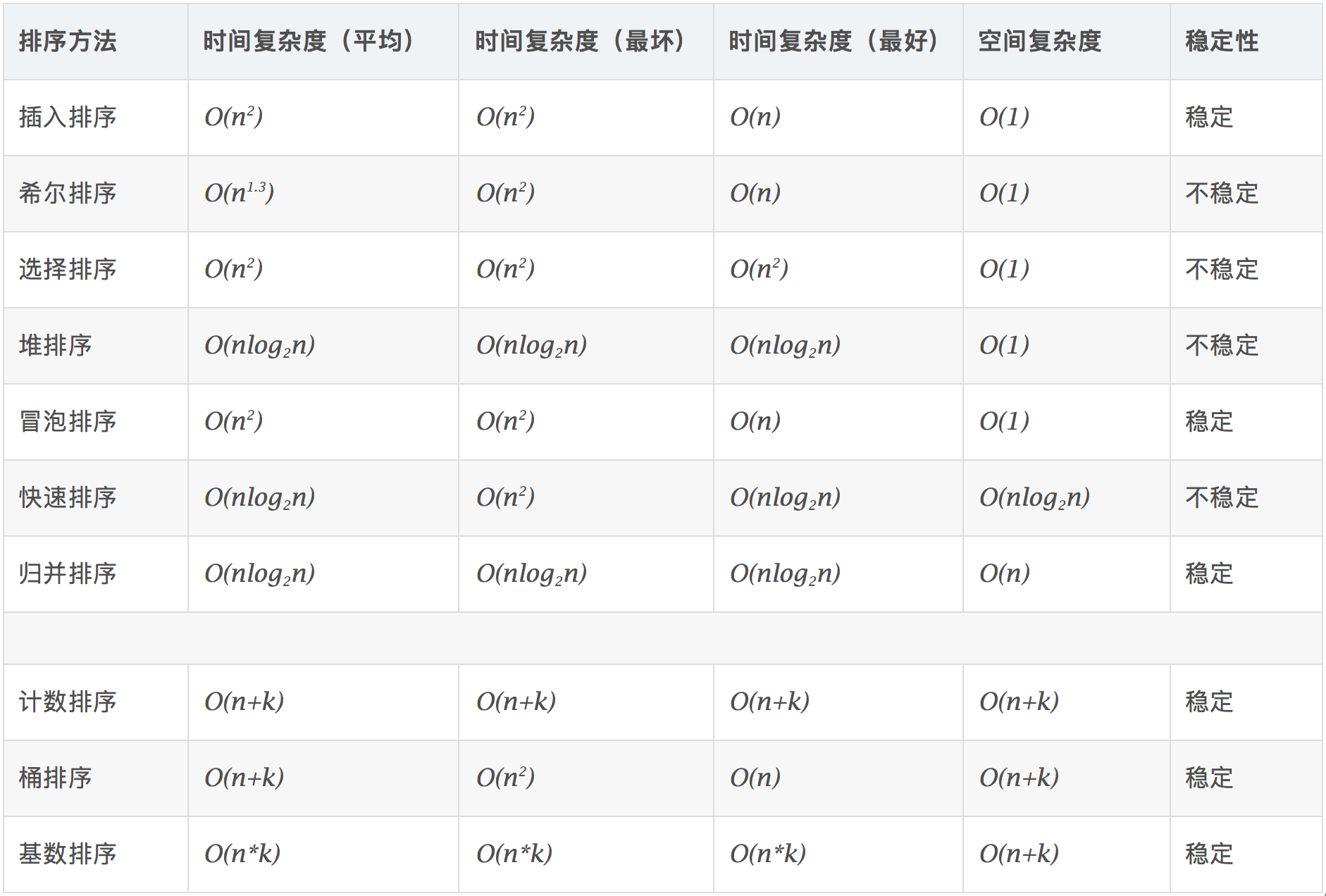
稳定:如果a原本在b前面,而a=b,排序之后a仍然在b的前面。
不稳定:如果a原本在b的前面,而a=b,排序之后 a 可能会出现在 b 的后面。
时间复杂度:对排序数据的总的操作次数。反映当n变化时,操作次数呈现什么规律。
空间复杂度:是指算法在计算机内执行时所需存储空间的度量,它也是数据规模n的函数。
关于时间复杂度和空间复杂度可参看其他文档.
1-冒泡排序(dubble)
理解,从第一个元素开始比较相邻元素的大小,如果LEFT 大于或者小于RIGHT 则交换元素,依次交换直到最后一个元素为最大的,所有元素都重复以上步骤,除了最后一个。
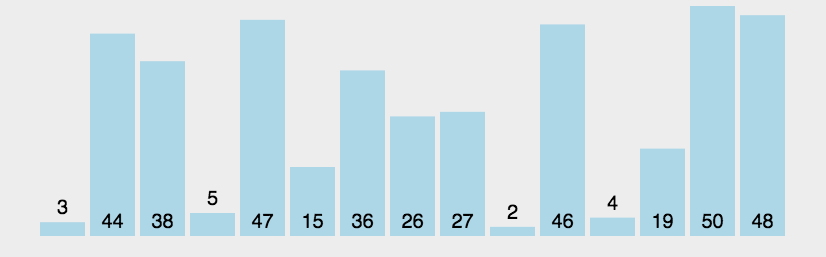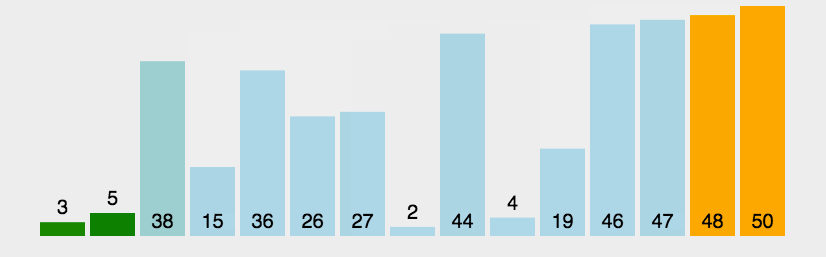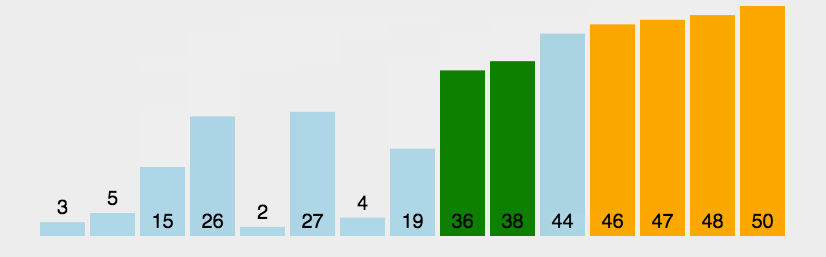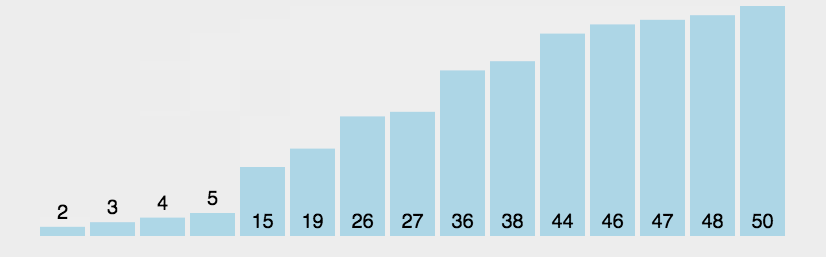
可以发现最差的情况是原来的排序和想要的排序是反的比如想要12345..N,初始值为N..54321,那么需要交换n + n(n-1)/2次, 时间复杂度O(n^2),最好的情况时间复杂度为O(n)。
public void bubbleSort(int []a){
int len=a.length;
for(int i=0;i<len;i++){
for(int j=0;j<len-i-1;j++){//注意第二重循环的条件
if(a[j]>a[j+1]){
int temp=a[j];
a[j]=a[j+1];
a[j+1]=temp;
}
}
}
}2-选择排序(selection)
1首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置。
2然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾,以此类推,直到所有元素均排序完毕。
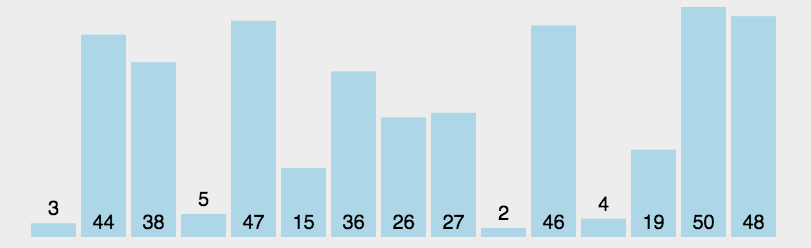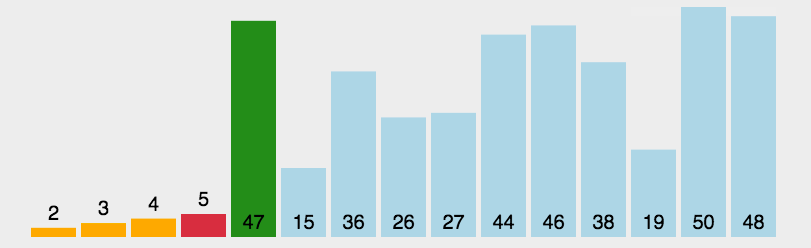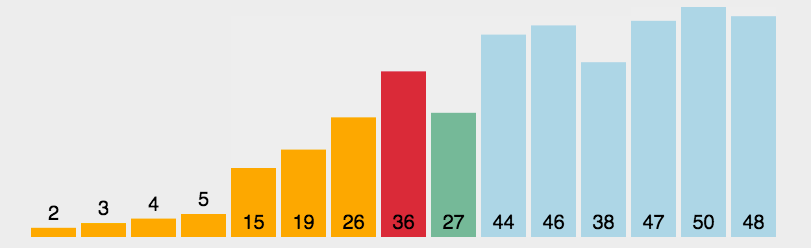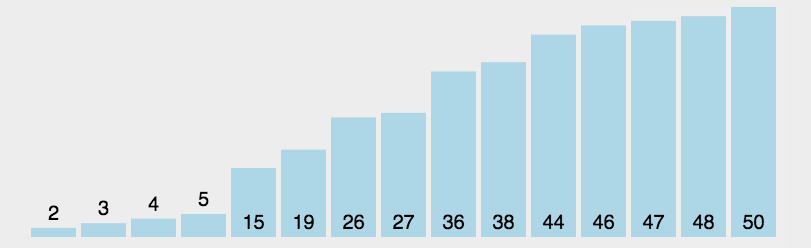
根据查找过程,第一次找了N-1次才找到最高的,以此类推,其需要找的次数为N-1 + N-2 + N-3 + … N-(N-1) = N + N(N-1)/2 ,忽略常数项,所以其时间复杂度为O(N^2)
public void selectSort(int[] a ){
int len = a.length;
for(int i = 0; i<len; i++){//循环次数
int value = a[i];
int position = i;
for(int j=i+1;j<len;j++){//找到最小的值和位置
if(a [j]< value){
value = a[j];
position = j;
}
}
a [position] = a[i];//进行交换
a[i] = value;
}
}
表现最稳定的排序算法之一,因为无论什么数据进去都是O(n2)的时间复杂度,所以用到它的时候,数据规模越小越好,好处可能就是不占用额外的内存空间。
插入排序(Insertion-Sort)的算法描述是一种简单直观的排序算法。
它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。
从第一个元素开始,该元素可以认为已经被排序;
取出下一个元素,在已经排序的元素序列中从后向前扫描;
如果该元素(已排序)大于新元素,将该元素移到下一位置;
重复步骤3,直到找到已排序的元素小于或者等于新元素的位置;
将新元素插入到该位置后;
重复步骤2~5。
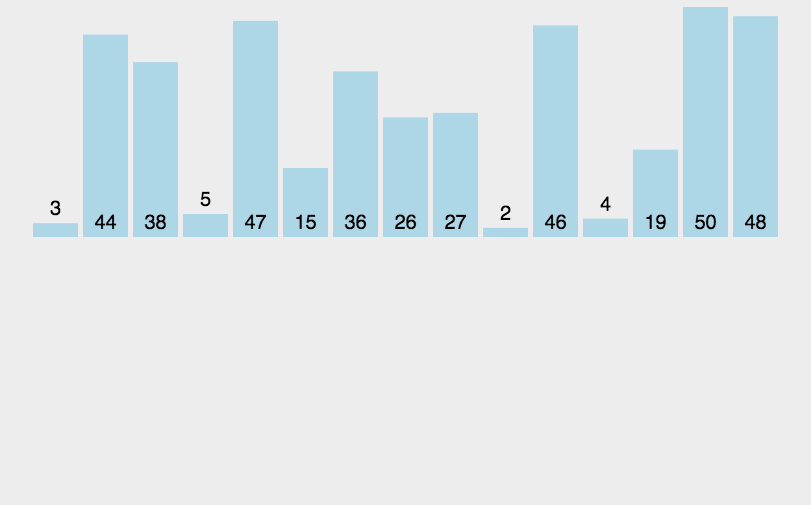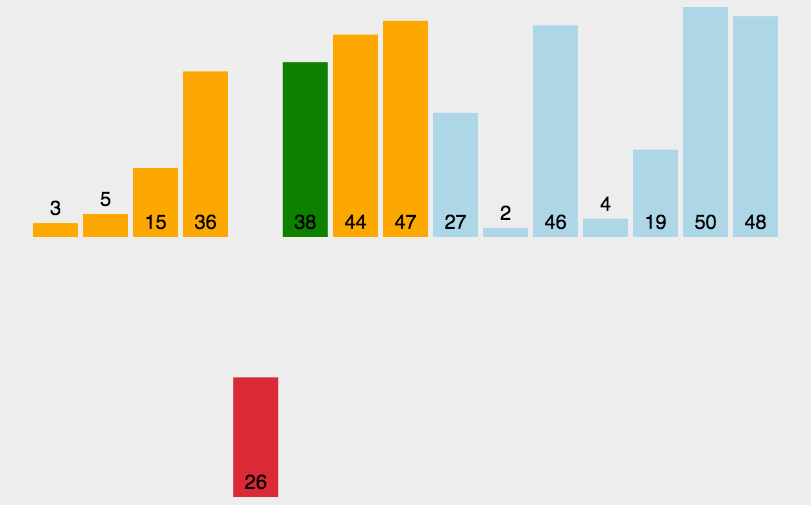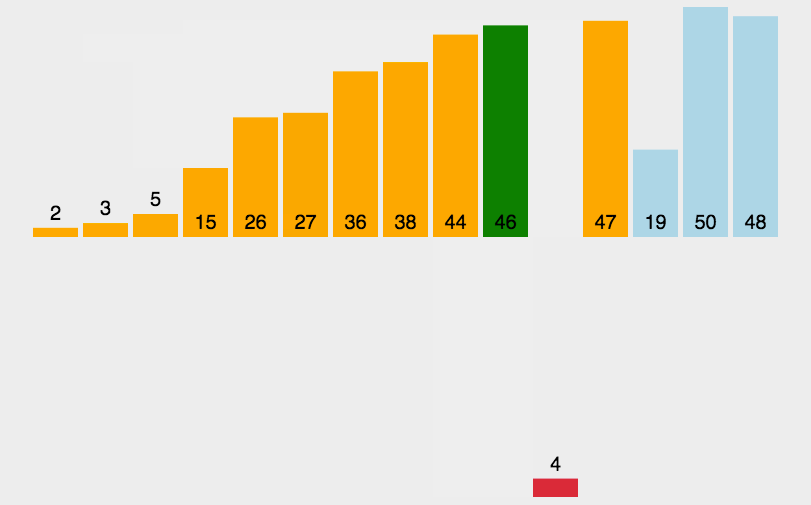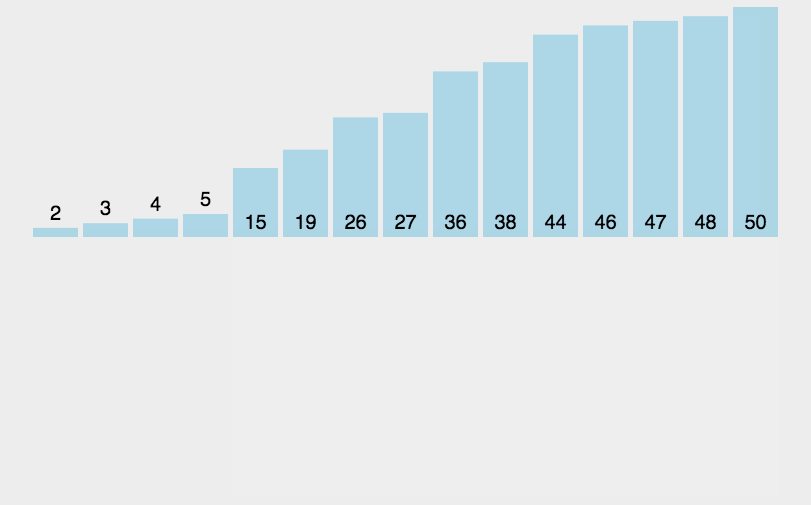
可以看到,最差的情况需要移动的次数为1+2+…N = N + N(N-1)/2 (等差数列的求和公式),所以其时间复杂度为O(N^2),最好的情况是移动N次,时间复杂度O(N)。
public void insertSort(int [] a){
int len=a.length;//单独把数组长度拿出来,提高效率
int insertNum;//要插入的数
for(int i=1;i<len;i++){//因为第一次不用,所以从1开始
insertNum=a[i];
int j=i-1;//序列元素个数
while(j>=0&&a[j]>insertNum){//从后往前循环,将大于insertNum的数向后移动
a[j+1]=a[j];//元素向后移动
j--;
}
a[j+1]=insertNum;//找到位置,插入当前元素
}
}4-希尔排序(shell)
第一个时间复杂度突破O(N^2)的排序算法,是插入排序的改进,其和插入排序的区别是,他先比较距离较远的元素,所以也叫缩小增量排序。
其算法是对待排序记录分割若干子序列分别进行直接插入排序。
将数的个数设为n,取奇数k=n/2,将下标差值为k的数分为一组,构成有序序列。
再取k=k/2 ,将下标差值为k的书分为一组,构成有序序列。
重复第二步,直到k=1执行简单插入排序,其平均时间复杂度为O(n^1.3)
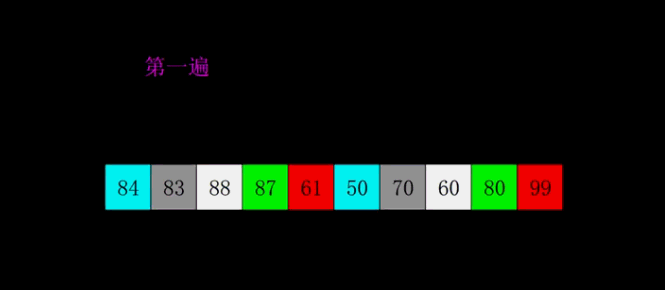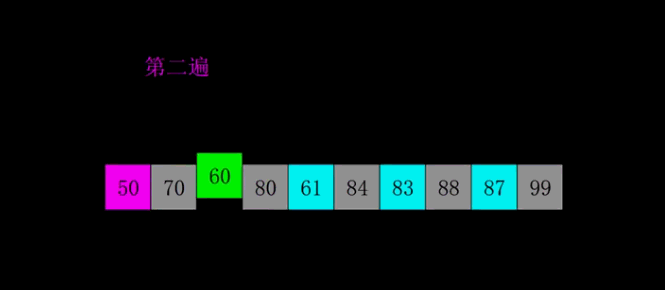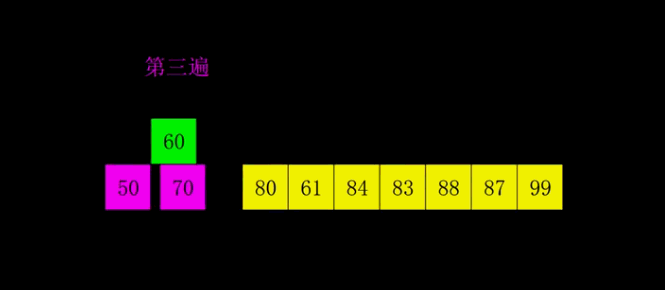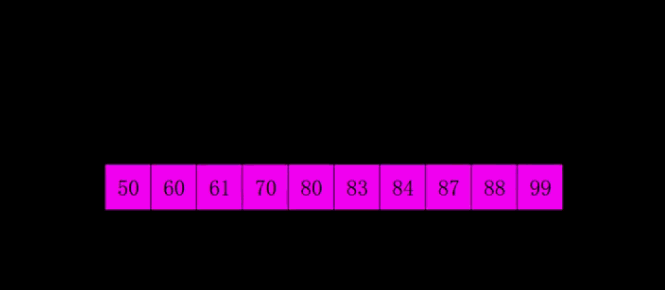
public void shellSort(int [] array){
int len = array.length;//单独把数组长度拿出来,提高效率
while(len != 0){
len = len/2;
for(int i = 0; i < len; i++){//分组
for(int j = i + len; j < array.length; j += len){ //元素从第二个开始
int k = j - len; //k为有序序列最后一位的位数
int temp = array[j]; //要插入的元素
while(k >= 0 && temp < array[k]){//从后往前遍历
array[k+len] = array[k];
k -= len;//向后移动len位
}
array[k+len] = temp;
}
}
}
}5-归并排序(merge)
归并排序是建立在归并操作上的一种有效的排序算法。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为2-路归并。
1 把长度为n的输入序列分成两个长度为n/2的子序列;
2 对这两个子序列分别采用归并排序;
3 将两个排序好的子序列合并成一个最终的排序序列。
public void mergeSort(int[] a, int left, int right) {
int t = 1;// 每组元素个数
int size = right - left + 1;
while (t < size) {
int s = t;// 本次循环每组元素个数
t = 2 * s;
int i = left;
while (i + (t - 1) < size) {
merge(a, i, i + (s - 1), i + (t - 1));
i += t;
}
if (i + (s - 1) < right)
merge(a, i, i + (s - 1), right);
}
}
private static void merge(int[] data, int p, int q, int r) {
int[] B = new int[data.length];
int s = p;
int t = q + 1;
int k = p;
while (s <= q && t <= r) {
if (data[s] <= data[t]) {
B[k] = data[s];
s++;
} else {
B[k] = data[t];
t++;
}
k++;
}
if (s == q + 1)
B[k++] = data[t++];
else
B[k++] = data[s++];
for (int i = p; i <= r; i++)
data[i] = B[i];
}
归并排序是一种稳定的排序方法,和选择排序一样,归并排序的性能不受输入数据的影响,但表现比选择排序好的多,因为始终都是O(nlogn)的时间复杂度。代价是需要额外的内存空间。
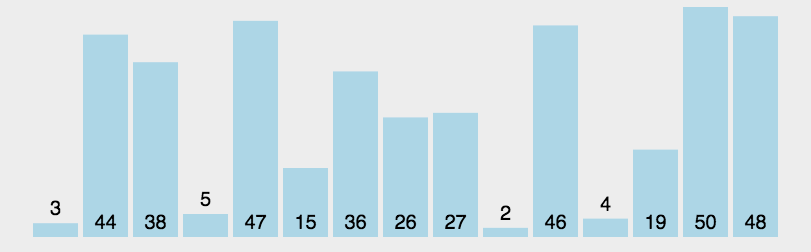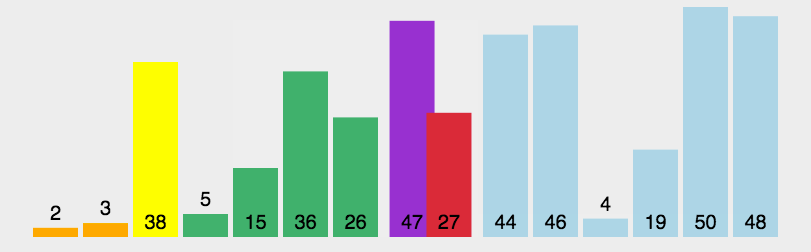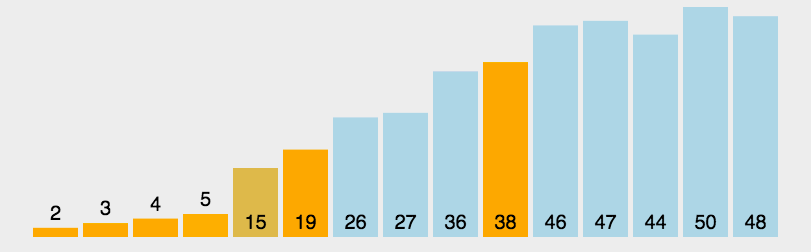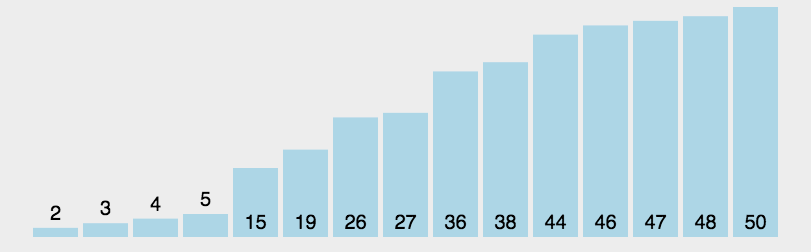
6-快速排序(quick)
快速排序的基本思想:通过一趟排序将待排记录分隔成独立的两部分,其中一部分记录的关键字均比另一部分的关键字小,则可分别对这两部分记录继续进行排序,以达到整个序列有序。
选择第一个数为p,小于p的数放在左边,大于p的数放在右边,递归的将p左边和右边的数都按照第一步进行,直到不能递归
public class QuickSort {
public static void quickSort(int[] arr,int low,int high){
int i,j,temp,t;
if(low>high){
return;
}
i=low;
j=high;
//temp就是基准位
temp = arr[low];
while (i<j) {
//先看右边,依次往左递减
while (temp<=arr[j]&&i<j) {
j--;
}
//再看左边,依次往右递增
while (temp>=arr[i]&&i<j) {
i++;
}
//如果满足条件则交换
if (i<j) {
t = arr[j];
arr[j] = arr[i];
arr[i] = t;
}
}
//最后将基准为与i和j相等位置的数字交换
arr[low] = arr[i];
arr[i] = temp;
//递归调用左半数组
quickSort(arr, low, j-1);
//递归调用右半数组
quickSort(arr, j+1, high);
}
public static void main(String[] args){
int[] arr = {10,7,2,4,7,62,3,4,2,1,8,9,19};
quickSort(arr, 0, arr.length-1);
for (int i = 0; i < arr.length; i++) {
System.out.println(arr[i]);
}
}
}
7-堆排序(Heap)
堆排序(Heapsort)是指利用堆这种数据结构所设计的一种排序算法。堆积是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。
将初始待排序关键字序列(R1,R2….Rn)构建成大顶堆,此堆为初始的无序区;
将堆顶元素R[1]与最后一个元素R[n]交换,此时得到新的无序区(R1,R2,……Rn-1)和新的有序区(Rn),且满足R[1,2…n-1]<=R[n];
由于交换后新的堆顶R[1]可能违反堆的性质,因此需要对当前无序区(R1,R2,……Rn-1)调整为新堆,然后再次将R[1]与无序区最后一个元素交换,得到新的无序区(R1,R2….Rn-2)和新的有序区(Rn-1,Rn)。不断重复此过程直到有序区的元素个数为n-1,则整个排序过程完成。

public void heapSort(int[] a) {
int len = a.length;
// 循环建堆
for (int i = 0; i < len - 1; i++) {
// 建堆
buildMaxHeap(a, len - 1 - i);
// 交换堆顶和最后一个元素
swap(a, 0, len - 1 - i);
}
}
// 交换方法
private void swap(int[] data, int i, int j) {
int tmp = data[i];
data[i] = data[j];
data[j] = tmp;
}
// 对data数组从0到lastIndex建大顶堆
private void buildMaxHeap(int[] data, int lastIndex) {
// 从lastIndex处节点(最后一个节点)的父节点开始
for (int i = (lastIndex - 1) / 2; i >= 0; i--) {
// k保存正在判断的节点
int k = i;
// 如果当前k节点的子节点存在
while (k * 2 + 1 <= lastIndex) {
// k节点的左子节点的索引
int biggerIndex = 2 * k + 1;
// 如果biggerIndex小于lastIndex,即biggerIndex+1代表的k节点的右子节点存在
if (biggerIndex < lastIndex) {
// 若果右子节点的值较大
if (data[biggerIndex] < data[biggerIndex + 1]) {
// biggerIndex总是记录较大子节点的索引
biggerIndex++;
}
}
// 如果k节点的值小于其较大的子节点的值
if (data[k] < data[biggerIndex]) {
// 交换他们
swap(data, k, biggerIndex);
// 将biggerIndex赋予k,开始while循环的下一次循环,重新保证k节点的值大于其左右子节点的值
k = biggerIndex;
} else {
break;
}
}
}
}
8-计数排序(counting)
计数排序不是基于比较的排序算法,其核心在于将输入的数据值转化为键存储在额外开辟的数组空间中。 作为一种线性时间复杂度的排序,计数排序要求输入的数据必须是有确定范围的整数。
找出待排序的数组中最大和最小的元素;
统计数组中每个值为i的元素出现的次数,存入数组C的第i项;
对所有的计数累加(从C中的第一个元素开始,每一项和前一项相加);
反向填充目标数组:将每个元素i放在新数组的第C(i)项,每放一个元素就将C(i)减去1。
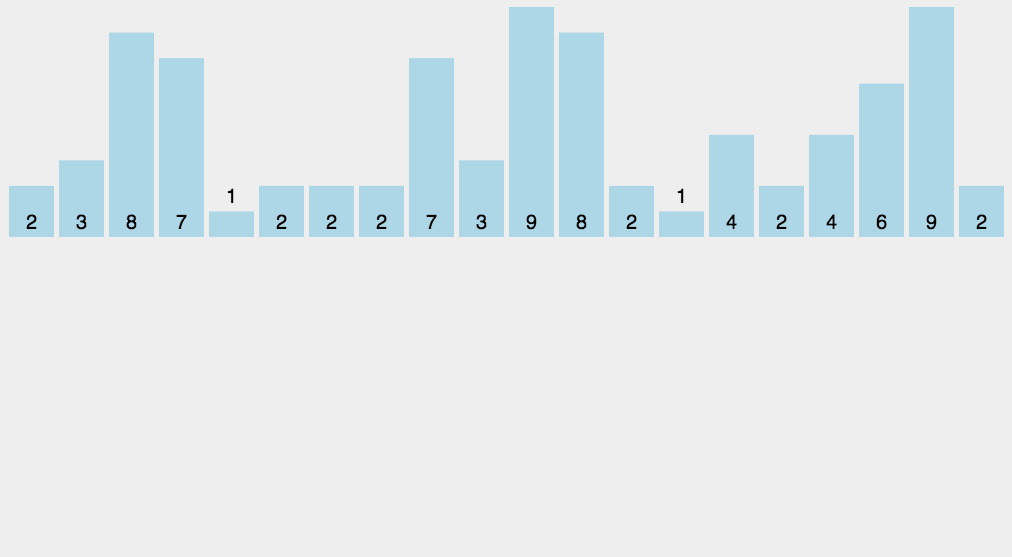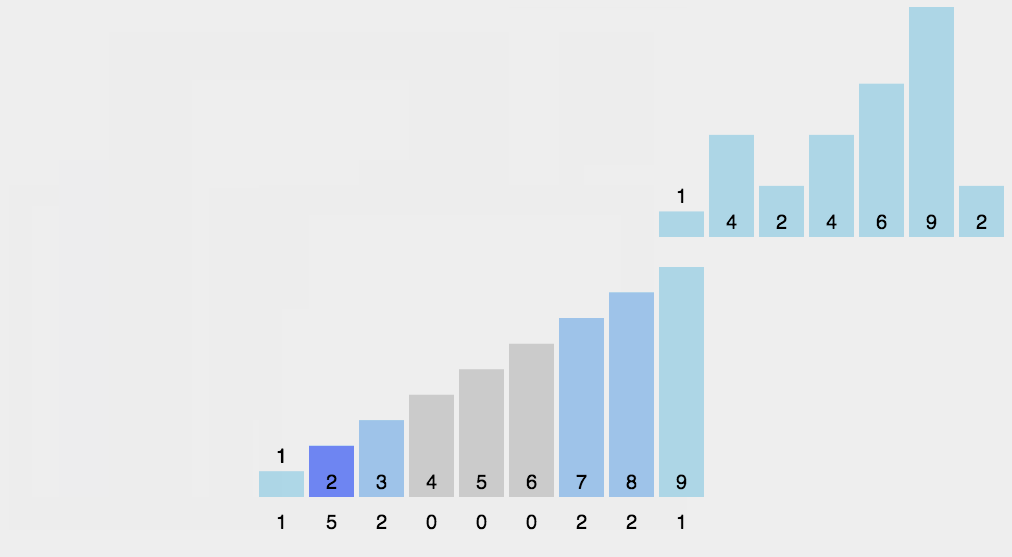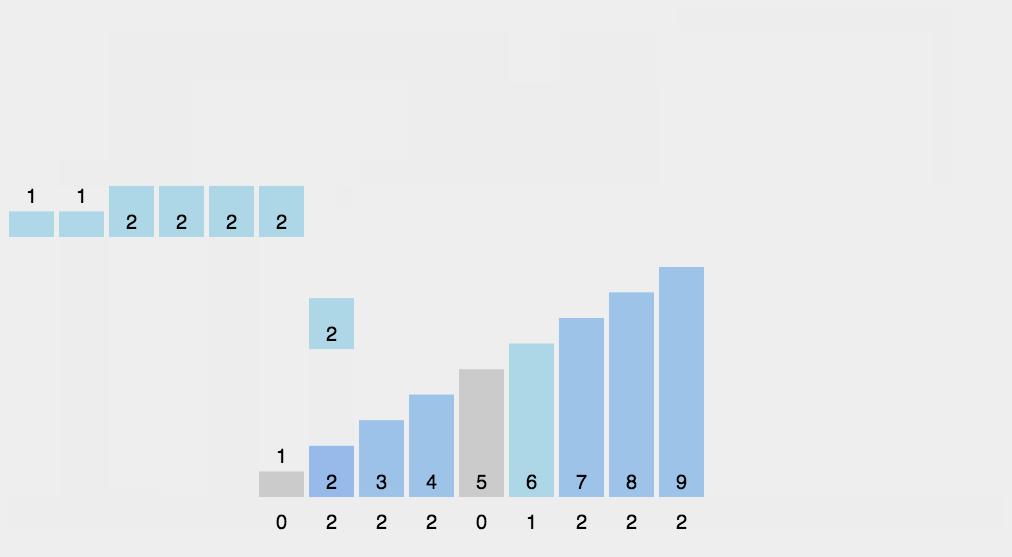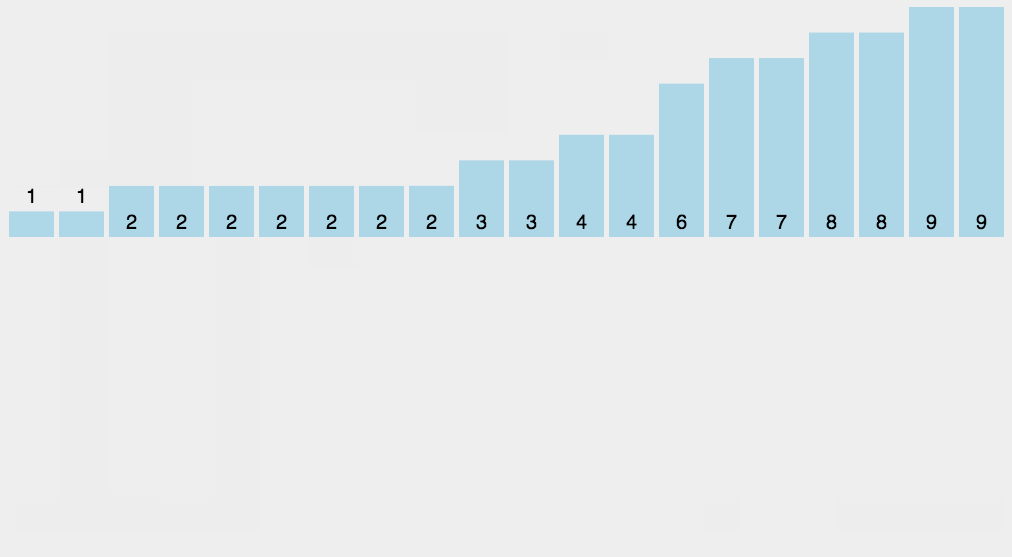
function countingSort(arr, maxValue) {
var bucket = new Array(maxValue + 1),
sortedIndex = 0;
arrLen = arr.length,
bucketLen = maxValue + 1;
for (var i = 0; i < arrLen; i++) {
if (!bucket[arr[i]]) {
bucket[arr[i]] = 0;
}
bucket[arr[i]]++;
}
for (var j = 0; j < bucketLen; j++) {
while(bucket[j] > 0) {
arr[sortedIndex++] = j;
bucket[j]--;
}
}
return arr;
}计数排序是一个稳定的排序算法。当输入的元素是 n 个 0到 k 之间的整数时,时间复杂度是O(n+k),空间复杂度也是O(n+k),其排序速度快于任何比较排序算法。当k不是很大并且序列比较集中时,计数排序是一个很有效的排序算法。
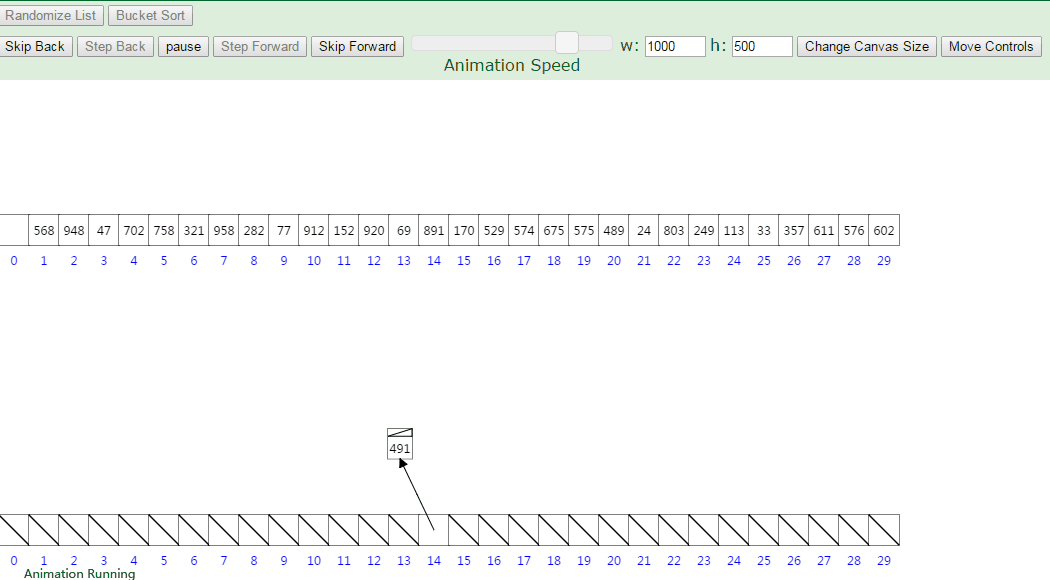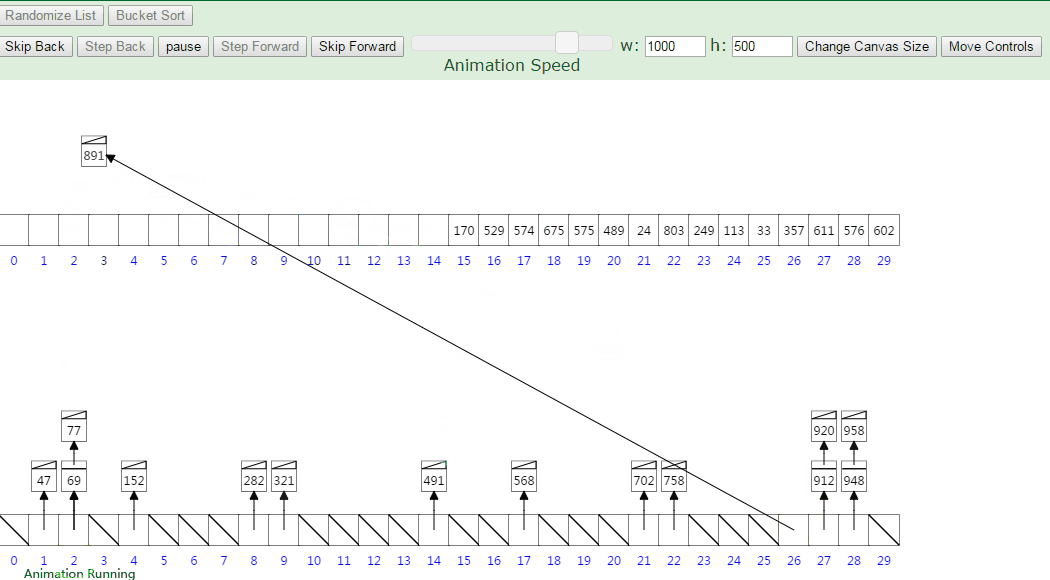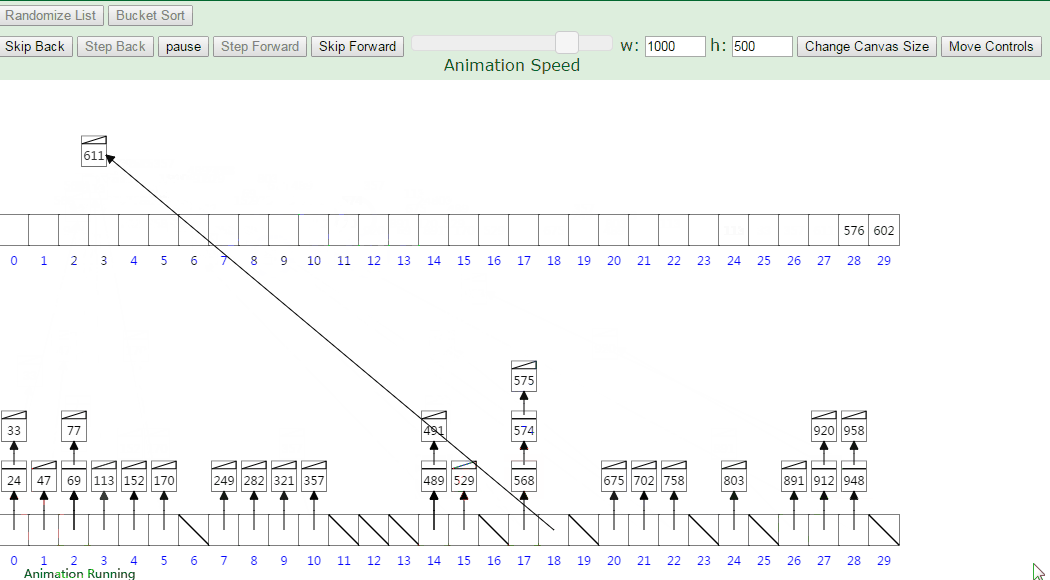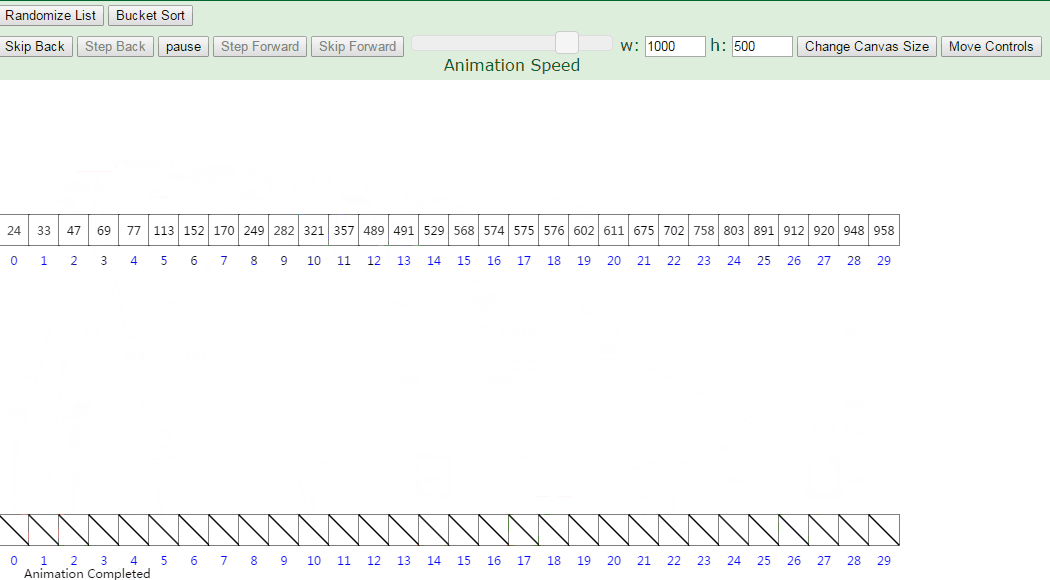
9-桶排序(Bucket)
桶排序是计数排序的升级版。它利用了函数的映射关系,高效与否的关键就在于这个映射函数的确定。桶排序 (Bucket sort)的工作的原理:假设输入数据服从均匀分布,将数据分到有限数量的桶里,每个桶再分别排序(有可能再使用别的排序算法或是以递归方式继续使用桶排序进行排)
设置一个定量的数组当作空桶;
遍历输入数据,并且把数据一个一个放到对应的桶里去;
对每个不是空的桶进行排序;
从不是空的桶里把排好序的数据拼接起来。
平均时间复杂度:O(n + k)
最佳时间复杂度:O(n + k)
最差时间复杂度:O(n ^ 2)
空间复杂度:O(n * k)
稳定性:稳定
可以看到,桶分的越细,桶中的数据越少,排序时间越短,但是增加了空间的占用。
function bucketSort(arr, bucketSize) {
if (arr.length === 0) {
return arr;
}
var i;
var minValue = arr[0];
var maxValue = arr[0];
for (i = 1; i < arr.length; i++) {
if (arr[i] < minValue) {
minValue = arr[i]; // 输入数据的最小值
} else if (arr[i] > maxValue) {
maxValue = arr[i]; // 输入数据的最大值
}
}
// 桶的初始化
var DEFAULT_BUCKET_SIZE = 5; // 设置桶的默认数量为5
bucketSize = bucketSize || DEFAULT_BUCKET_SIZE;
var bucketCount = Math.floor((maxValue - minValue) / bucketSize) + 1;
var buckets = new Array(bucketCount);
for (i = 0; i < buckets.length; i++) {
buckets[i] = [];
}
// 利用映射函数将数据分配到各个桶中
for (i = 0; i < arr.length; i++) {
buckets[Math.floor((arr[i] - minValue) / bucketSize)].push(arr[i]);
}
arr.length = 0;
for (i = 0; i < buckets.length; i++) {
insertionSort(buckets[i]); // 对每个桶进行排序,这里使用了插入排序
for (var j = 0; j < buckets[i].length; j++) {
arr.push(buckets[i][j]);
}
}
return arr;
}10-基数排序(radix)
基本思想:将所有待比较数值(正整数)统一为同样的数位长度,数位较短的数前面补零。然后,从最低位开始,依次进行一次排序。这样从最低位排序一直到最高位排序完成以后,数列就变成一个有序序列。

public class radixSort {
int a[] = { 49, 38, 65, 97, 76, 13, 27, 49, 78, 34, 12, 64, 5, 4, 62, 99, 98, 54, 101, 56, 17, 18, 23, 34, 15, 35,25, 53, 51 };
public radixSort() {
sort(a);
for (int i = 0; i < a.length; i++) {
System.out.println(a[i]);
}
}
public void sort(int[] array) {
// 首先确定排序的趟数;
int max = array[0];
for (int i = 1; i < array.length; i++) {
if (array[i] > max) {
max = array[i];
}
}
int time = 0;
// 判断位数;
while (max > 0) {
max /= 10;
time++;
}
// 建立10个队列;
List<ArrayList> queue = new ArrayList<ArrayList>();
for (int i = 0; i < 10; i++) {
ArrayList<Integer> queue1 = new ArrayList<Integer>();
queue.add(queue1);
}
// 进行time次分配和收集;
for (int i = 0; i < time; i++) {
// 分配数组元素;
for (int j = 0; j < array.length; j++) {
// 得到数字的第time+1位数;
int x = array[j] % (int) Math.pow(10, i + 1) / (int) Math.pow(10, i);
ArrayList<Integer> queue2 = queue.get(x);
queue2.add(array[j]);
queue.set(x, queue2);
}
int count = 0;// 元素计数器;
// 收集队列元素;
for (int k = 0; k < 10; k++) {
while (queue.get(k).size() > 0) {
ArrayList<Integer> queue3 = queue.get(k);
array[count] = queue3.get(0);
queue3.remove(0);
count++;
}
}
}
}
}总结
一、稳定性:
稳定:冒泡排序、插入排序、归并排序和基数排序
不稳定:选择排序、快速排序、希尔排序、堆排序
二、平均时间复杂度
O(n^2):直接插入排序,简单选择排序,冒泡排序。
在数据规模较小时(9W内),直接插入排序,简单选择排序差不多。
当数据较大时,冒泡排序算法的时间代价最高。性能为O(n^2)的算法基本上是相邻元素进行比较,基本上都是稳定的。
O(nlogn):快速排序,归并排序,希尔排序,堆排序。其中,快速排序是最好的, 其次是归并和希尔,堆排序在数据量很大时效果明显。
三、排序算法的选择
1.数据规模较小
(1)待排序列基本序的情况下,可以选择直接插入排序;
(2)对稳定性不作要求宜用简单选择排序,对稳定性有要求宜用插入或冒泡。
2.数据规模不是很大
(1)完全可以用内存空间,序列杂乱无序,对稳定性没有要求,快速排序,此时要付出log(N)的额外空间。
(2)序列本身可能有序,对稳定性有要求,空间允许下,宜用归并排序。
3.数据规模很大
(1)对稳定性有求,则可考虑归并排序。
(2)对稳定性没要求,宜用堆排序。
4.序列初始基本有序(正序),宜用直接插入排序,冒泡排序。
参考
一盏灯, 一片昏黄; 一简书, 一杯淡茶。 守着那一份淡定, 品读属于自己的寂寞。 保持淡定, 才能欣赏到最美丽的风景! 保持淡定, 人生从此不再寂寞。




