本文主要介绍STORM,以及storm集群的安装和使用
什么是storm
Apache Storm是自由开源的分布式实时计算系统,擅长处理海量数据,适用于数据实时处理而非批处理。
批处理使用的大多是鼎鼎大名的hadoop或者hive,作为一个批处理系统,hadoop以其吞吐量大、自动容错等优点,在海量数据处理上得到了广泛的使用。但是,hadoop不擅长实时计算,因为它天然就是为批处理而生的,这也是业界一致的共识。否则最近几年也不会有s4,storm,puma这些实时计算系统如雨后春笋般冒出来啦。STORM就是为了处理及时的消费者请求而生,在用户给出需求时及时的处理数据并给出响应的结果。
storm处理流程
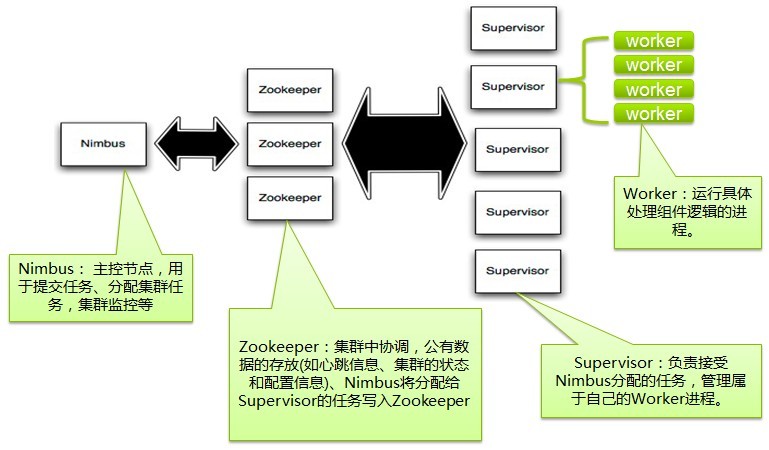
可以看出storm的数据处理是交给ZK处理分发的,由nimbus管理supervisor,supervis管理worker,worker才是真正做数据处理的进程,worker提交TASK,类似多线程提交任务,整个流程达到消息的实时处理能力。
spout和bolt
spout
spout是数据源,例如spout可以调用 Twitter API 得到一个微博数据流,就是从外部数据源(队列、数据库等)中读取数据,封装成元组,形成STREAM数据流。
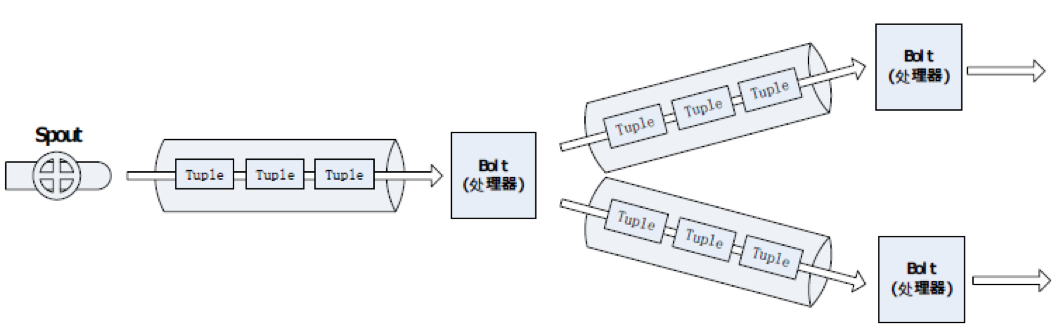
bolt
bolt是用来处理数据的,可以对一些数据流(不只一个数据流)进行处理,可能会产生新的STREAM数据流。对一些复杂的数据流变换,
比如从一个微博流中计算一个热门话题流,就需要很多步骤,因此就有多个bolt,因此bolt中就有很多处理,比如运行函数,做流式聚合,流式链接,访问数据库等等。
不同的bolt可以订阅相同的spout来达到消息共享的目的,比如来了一条数据,bolt1是做数据入库处理,bolt2只是做简单的日志记录,bolt3….
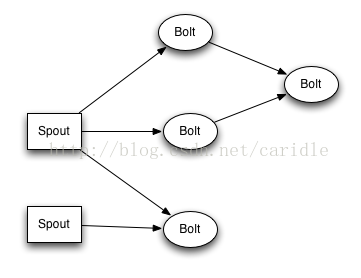
topology
如上图所示 topology就是spout 和 bolt组成的网络拓扑图,Topology就是最高层的逻辑抽象,可以直接送到 Storm 集群去执行。一个Topology图就是流式转换,每个节点是 spout 或者 bolt,图中的每条边就是 bolt 订阅了流,当一个 spout或者 bolt 产生一个元组到一个流时,它就发送元组到订阅了流的每个 bolt。
自定义topology并提交topology到storm集群
1.首先需要实现storm的spout和bolt接口实现对stream流数据的接收和处理
package cn.xpleaf.bigdata.storm.remote;
import cn.xpleaf.bigdata.storm.utils.StormUtil;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.generated.StormTopology;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import java.util.Date;
import java.util.Map;
/**
* 1°、实现数字累加求和的案例:数据源不断产生递增数字,对产生的数字累加求和。
* <p>
* Storm组件:Spout、Bolt、数据是Tuple,使用main中的Topology将spout和bolt进行关联
* MapReduce的组件:Mapper和Reducer、数据是Writable,通过一个main中的job将二者关联
* <p>
* 适配器模式(Adapter):BaseRichSpout,其对继承接口中一些没必要的方法进行了重写,但其重写的代码没有实现任何功能。
* 我们称这为适配器模式
*/
public class StormSumTopology {
/**
* 数据源
*/
static class OrderSpout extends BaseRichSpout {
private Map conf; // 当前组件配置信息
private TopologyContext context; // 当前组件上下文对象
private SpoutOutputCollector collector; // 发送tuple的组件
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.conf = conf;
this.context = context;
this.collector = collector;
}
/**
* 接收数据的核心方法
*/
@Override
public void nextTuple() {
long num = 0;
while (true) {
num++;
StormUtil.sleep(1000);
System.out.println("当前时间" + StormUtil.df_yyyyMMddHHmmss.format(new Date()) + "产生的订单金额:" + num);
this.collector.emit(new Values(num));
}
}
/**
* 是对发送出去的数据的描述schema
*/
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("order_cost"));
}
}
/**
* 计算和的Bolt节点
*/
static class SumBolt extends BaseRichBolt {
private Map conf; // 当前组件配置信息
private TopologyContext context; // 当前组件上下文对象
private OutputCollector collector; // 发送tuple的组件
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.conf = conf;
this.context = context;
this.collector = collector;
}
private Long sumOrderCost = 0L;
/**
* 处理数据的核心方法
*/
@Override
public void execute(Tuple input) {
Long orderCost = input.getLongByField("order_cost");
sumOrderCost += orderCost;
System.out.println("商城网站到目前" + StormUtil.df_yyyyMMddHHmmss.format(new Date()) + "的商品总交易额" + sumOrderCost);
StormUtil.sleep(1000);
}
/**
* 如果当前bolt为最后一个处理单元,该方法可以不用管
*/
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}
/**
* 构建拓扑,相当于在MapReduce中构建Job
*/
public static void main(String[] args) throws Exception {
TopologyBuilder builder = new TopologyBuilder();
/**
* 设置spout和bolt的dag(有向无环图)
*/
builder.setSpout("id_order_spout", new OrderSpout());
builder.setBolt("id_sum_bolt", new SumBolt()).shuffleGrouping("id_order_spout"); // 通过不同的数据流转方式,来指定数据的上游组件
// 使用builder构建topology
StormTopology topology = builder.createTopology();
String topologyName = StormSumTopology.class.getSimpleName(); // 拓扑的名称
Config config = new Config(); // Config()对象继承自HashMap,但本身封装了一些基本的配置
// 启动topology,本地启动使用LocalCluster,集群启动使用StormSubmitter
if (args == null || args.length < 1) { // 没有参数时使用本地模式,有参数时使用集群模式
LocalCluster localCluster = new LocalCluster(); // 本地开发模式,创建的对象为LocalCluster
localCluster.submitTopology(topologyName, config, topology);
} else {
StormSubmitter.submitTopology(topologyName, config, topology);
}
}
}2.将spout和bolt接口以及其他配置类组成的topology的jar包放入到指定的目录中(最好放在storm的nimbus节点下),注意打包方式确保JAR包下有storm-core相关依赖包.
3.执行命令提交topology的JAR到storm的集群
#先切换到strom 的bin目录,然后执行以下命令
bin/storm kill topology #执行KILL操作时候可能会报没有此topology错误,可以不用理会
sleep 5
# 类似JAVA -JAR 方式启动JAR包,后面的bootstrap-servers根据业务而定,可要可不要.
bin/storm jar topology/topology-1.0.0.jar com.company.ApplicationLoader --bootstrap-serverIp1=ip1:9092,serverIp2:9092,serverIp3:90924.通过nimbus的UI端口查看topology的运行情况,以及异常情况
storm 核心逻辑
Nimbus:Storm集群主节点,负责资源分配和任务调度。我们提交任务和截止任务都是在Nimbus上操作的。一个Storm集群只有一个Nimbus节点。
Supervisor:Storm集群工作节点,接受Nimbus分配任务,管理所有Worker。
Worker:工作进程,每个工作进程中都有多个Task。
Task:任务,每个Spout和Bolt都是一个任务,每个任务都是一个线程。
Topology:计算拓扑,包含了应用程序的逻辑。
Stream:消息流,关键抽象,是没有边界的Tuple序列。
Spout:消息流的源头,Topology的消息生产者。
Bolt:消息处理单元,可以过滤、聚合、查询数据库。
Stream grouping:消息分发策略,一共6种,定义每个Bolt接受何种输入。
Reliability:可靠性,Storm保证每个Tuple都会被处理。
Storm安装部署
zookeeper集群安装
略,请自行查看文档安装,这个比较简单
搭建storm集群
下载storm包,目前已经更新到2.0版本,下载地址>http://storm.apache.org/index.html
1.解压
[uplooking@uplooking01 soft]$ tar -zxvf apache-storm-1.0.2.tar.gz -C ../app/
[uplooking@uplooking01 app]$ mv apache-storm-1.0.2/ storm2.修改配置文件 storm-env.sh
export JAVA_HOME=/opt/jdk
export STORM_CONF_DIR="/home/uplooking/app/storm/conf"3. 修改storm.yaml
storm.zookeeper.servers:
- "uplooking01"
- "uplooking02"
- "uplooking03"
nimbus.seeds: ["uplooking01", "uplooking02"]
storm.local.dir: "/home/uplooking/data/storm" # 日志目录
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
storm.zookeeper.port: 2181 #zookeeper端口配置
ui.port: 8000 #ui 端口设置4.创建storm.local.dir
mkdir -p /home/uplooing/data/storm5.配置环境变量
# .bash_profile
export STORM_HOME=/home/uplooking/app/storm
export PATH=$PATH:$STORM_HOME/bin6.将其同步到其它节点
scp .bash_profile uplooking@uplooking02:/home/uplooking
scp .bash_profile uplooking@uplooking03:/home/uplooking7.复制storm安装目录到其它节点
scp -r storm/ uplooking@uplooking02:/home/uplooking/app
scp -r storm/ uplooking@uplooking03:/home/uplooking/app8.启动storm集群
# uplooking01
storm nimbus &
storm ui &
# uplooking02
storm nimbus &
storm supervisor &
# uplooking03
storm supervisor &9.启动logviewer(可选)
在所有从节点执行"nohup bin/storm logviewer >/dev/null 2>&1 &"启动log后台程序,并放到后台执行。
(nimbus节点可以不用启动logviewer进程,因为logviewer进程主要是为了方便查看任务的执行日志,这些执行日志都在supervisor节点上)。总结
storm作为一款高效的数据流实时处理框架得到了广泛的使用,解决了Hadoop、spark在数据处理方面的性能问题,对JAVA良好的支持使得其在商业上应用更加广泛.
此文是自己学习和使用了storm集群的一些理解和体会,如有错误,欢迎指正.
一盏灯, 一片昏黄; 一简书, 一杯淡茶。 守着那一份淡定, 品读属于自己的寂寞。 保持淡定, 才能欣赏到最美丽的风景! 保持淡定, 人生从此不再寂寞。




