概述
本文主要介绍hashmap的原理和说明
hashMap 部分源码说明
put 方法
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node<K,V>[] tab; Node<K,V> p; int n, i; if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length; if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null); else { Node<K,V> e; K k; if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); else { for (int binCount = 0; ; ++binCount) { if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st this will change linkList to red-black tree treeifyBin(tab, hash); break; } if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; p = e; } } if (e != null) { // existing mapping for key V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) e.value = value; afterNodeAccess(e); return oldValue; } } ++modCount; if (++size > threshold) resize(); afterNodeInsertion(evict); return null; }
转为TreeNode过程
/** * Replaces all linked nodes in bin at index for given hash unless * table is too small, in which case resizes instead. */ final void treeifyBin(Node<K,V>[] tab, int hash) { int n, index; Node<K,V> e; if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY) resize(); else if ((e = tab[index = (n - 1) & hash]) != null) { TreeNode<K,V> hd = null, tl = null; do { TreeNode<K,V> p = replacementTreeNode(e, null); if (tl == null) hd = p; else { p.prev = tl; tl.next = p; } tl = p; } while ((e = e.next) != null); if ((tab[index] = hd) != null) hd.treeify(tab); } }
> TreeNode对象
```java
/**
* Entry for Tree bins. Extends LinkedHashMap.Entry (which in turn
* extends Node) so can be used as extension of either regular or
* linked node.
*/
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent; // red-black tree links
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red;
TreeNode(int hash, K key, V val, Node<K,V> next) {
super(hash, key, val, next);
}
/**
* Returns root of tree containing this node.
*/
final TreeNode<K,V> root() {
for (TreeNode<K,V> r = this, p;;) {
if ((p = r.parent) == null)
return r;
r = p;
}
}
}可以看出在链表中容量大于等于8后,链表转为了红黑树以提高hashmap性能,此JDK为1.8。
HashMap和Hashtable的区别
Hashtable是基于陈旧的Dictionary类的,HashMap是java 1.2引进的Map接口的一个现实。
Hashtable是同步的,这个类中的一些方法保证了Hashtable中的对象是线程安全的
HashMap则是异步的,因此HashMap中的对象并不是线程安全的,因为同步的要求会影响执行的效率,所以如果你不需要线程安全的结合那么使用HashMap是一个很好的选择,这样可以避免由于同步带来的不必要的性能开销,从而提高效率,我们一般所编写的程序都是异步的,但如果是服务器端的代码除外。
HashMap可以将空值作为一个表的条目的key或value, Hashtable不能放入空值(null).
HashMap说明
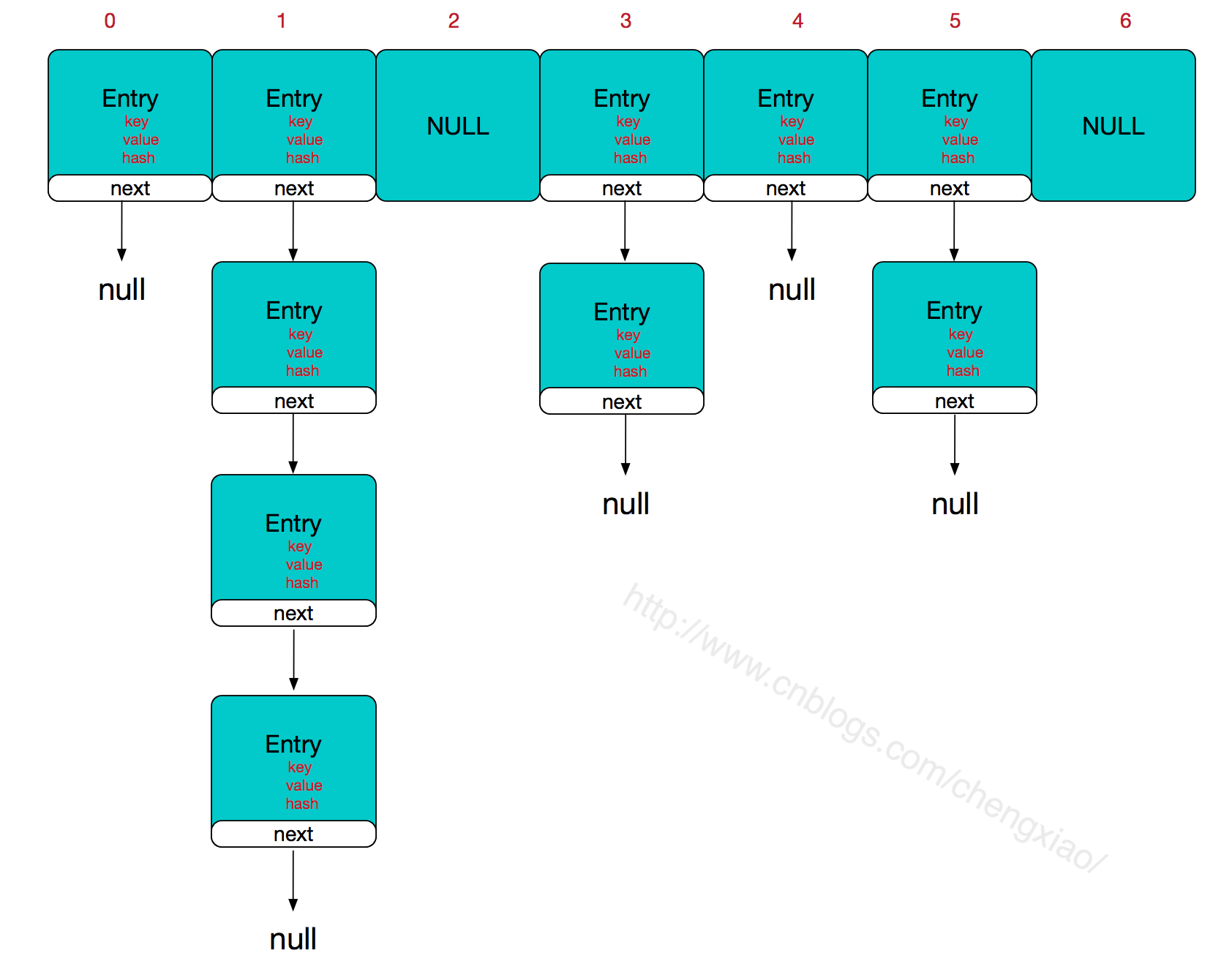
HashMap 的底层实现是数组,这大大加快了其速率,hashMap的快来源于hash表,而hash表的主干就是数组.
hash表为何快呢,hashMap在查找和增加元素时会先通过KEY去hash表中找到其引用的实际存储地址,从而操作该数据,其数据其实是一个ENTRY对象.
hash冲突,当对某个元素通过hash计算得到的的存储地址,在插入时发现此地址已经被其他元素占用,则产生hash冲突.
哈希冲突的解决方案有多种:开放定址法(发生冲突,继续寻找下一块未被占用的存储地址),再散列函数法,链地址法,而HashMap即是采用了链地址法,也就是数组+链表的方式(JDK7之前),JDK8采用的是数组+链表/红黑树的方式。当同一个hash值的节点数大于8时,将不再以单链表的形式存储了,会被调整成一颗红黑树,这就是JDK7与JDK8中HashMap实现的最大区别。
简单来说,HashMap由数组+链表组成的,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的,如果定位到的数组位置不含链表(当前entry的next指向null),那么对于查找,添加等操作很快,仅需一次寻址即可;
如果定位到的数组包含链表,对于添加操作,其时间复杂度为O(n),首先遍历链表,存在即覆盖,否则新增;对于查找操作来讲,仍需遍历链表,然后通过key对象(比如student)的equals方法逐一比对查找。so,性能考虑,HashMap中的链表出现越少,性能才会越好。
hashMap threshold 指当前map容量达到threshold%时对hashMap进行扩容,默认为0.75
如何减少hash冲突,使用final对象作为key,并且从写equal方法,hashcode方法,提高hashcode性能。
两个键的hashcode相同,如何获取值对象
如果两个键的hashcode相同,即找到bucket位置之后,我们通过key.equals()找到链表LinkedList中正确的节点,最终找到要找的值对象。
object.equal()方法只判断两个引用变量是否为同一个对象,无法真的判断对象在逻辑上是否相等.
所以尽量使用不可变的、声明作final的对象,并且采用合适的equals()和hashCode()方法,减少碰撞的发生,提高效率。不可变性使得能够缓存不同键的hashcode,这将提高整个获取对象的速度,使用String,Interger这样的wrapper类作为键是非常好的选择。
CocurrentHashMap为什么线程安全
CocurrentHashMap使用了分段锁技术:ConcurrentHashMap的主干是个Segment数组,ConcurrentHashMap相比HashTable而言解决的问题就是的它不是锁全部数据,而是锁一部分数据,这样多个线程访问的时候就不会出现竞争关系,不需要排队等待了。
ConcurrentHashMap是分段并发分段进行读取数据的,Segment 里面有一个Count字段,用来表示当前Segment中元素的个数它的类型是volatile变量。所有的操作到最后都会在最后一步更新count这个变量,由于volatile变量 happer-before的特性使得get方法能够几乎准确的获取最新的结构更新。
参考
一盏灯, 一片昏黄; 一简书, 一杯淡茶。 守着那一份淡定, 品读属于自己的寂寞。 保持淡定, 才能欣赏到最美丽的风景! 保持淡定, 人生从此不再寂寞。




